延續前一個主題針對 CachedPage 做 crawl, 我有了目標網站在 Cached Page Server 上還存留的清單, 接下來要進行較為複雜的爬蟲工作 (反覆的解析原始網頁內容、抓取圖片), 這時候之前學會的技巧就遇到了一些問題
之前的架構 是循序, 透過 Requests 抓取 html content 解析網址, 再使用 BeautifulSoup, bs4 去將 html 轉成結構化的物件, 透過此 lib 的協助提取所需要的內文資訊。
- Performance 循序的方式會造成因為 I/O wait 的時間太久, 導致這些連續需要 I/O 的工作, 大部分的時間都花在等待連線上。
- Data 大量蒐集的資料要如何存放, 以方便為後續作業上的使用保留彈性。Next Topic
Official Tutorial
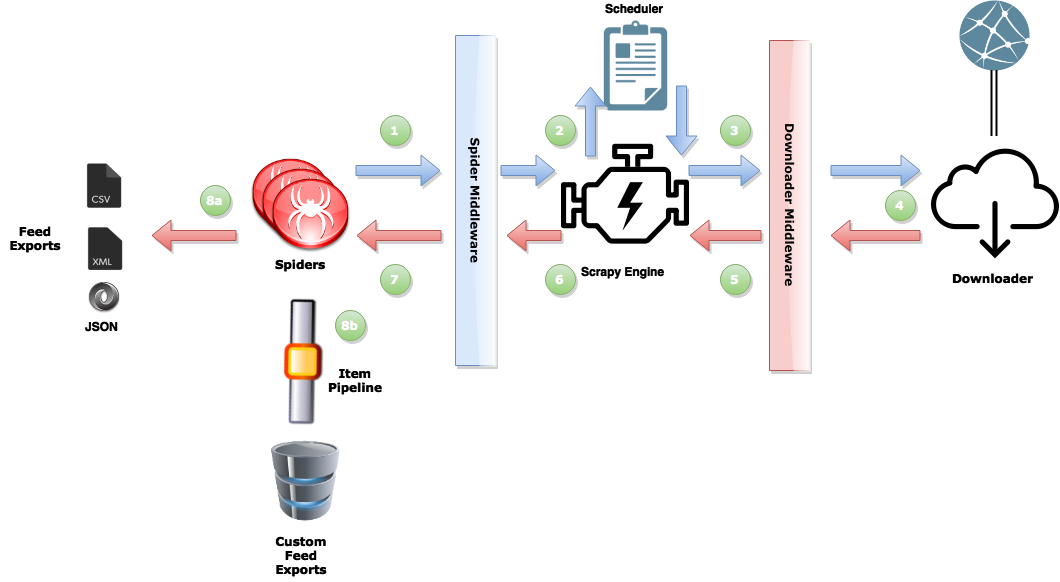 dataflow reference form The ITC Prog Blog
dataflow reference form The ITC Prog Blog
Brief Overview
- The spider schedules requests for download (1)
- The engine manages these requests and then executes them concurrently (2,3)
- When the response is available (4) the engine sends it back to the spider (5,6)
- The spider then scrapes the response (7) and either returns more requests to the scheduler (1), or returns scraped items from the webpage (8a,8b).
從上圖知道, 左半邊是我們要處理的核心工作, 後面也將為各位一一介紹如何開始。
Create Project
scrapy startproject MySpider
MySpider 為新建的 project name, 可自行命名
MySpider
|-- MySpider
| |-- __init__.py
| |-- items.py
| |-- middlewares.py
| |-- pipelines.py
| |-- settings.py
| `-- spiders
| `-- __init__.py
`-- scrapy.cfg
筆者目前 project 有修改、新增的檔案
- spiders/
<spider name> - items.py
- pipelines.py
- settings.py
Spider
spiders/exmaple.py
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
#allowed_domains = ['domain url']
start_urls = [
'http://www.google.com.tw',
]
def parse(self, response):
(...)
yield scrapy.Request(url, callback)
- name 是用來定義執行時的名稱 ex.
scrapy crawl myspider - allowed_domains 用來限制允許的連線
- start_urls 起始抓取的頁面, 得到 response 會呼叫 parse 這支 callback
- parse 從 start_urls 得到 response, 可將此視為爬蟲主程式的進入點, 將 response 的內容提取出下一步要爬取的網址, 再透過 yield 送出 request, 而 requset 取得的內容, 可自行再定義連結至哪個 function 來作為 callback
Item
item 為 scrapy framework 中用來串接 pipeline 動作的資料結構, 在 item.py 中先定義出此資料的內容
item.py
class MyspiderItem(scrapy.Item):
# define the fields for your item here like:
person = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
- person 為筆者示範如何自行定義欄位, 可透過相同的宣告方式來新增多個資料存放欄位, 但這裡 image_urls、images 為特殊欄位, 當 item 宣告這兩個欄位並在 settings.py 中去 enable ImagesPipeline, 便可以在爬蟲執行過程中透過對 image_urls list 加入 image url, 讓 scrapy 自行下載 (透過內建的 ImagesPipeline) 並把下載完的狀態存放至 images 這個 list 之中。
Pipeline
Pipeline 用來對 spider 撈出的資料 (要先存放至 item 中) 進行進一步的操作, ex. 寫入資料庫
pipelines.py
class MyspiderPipeline(object):
def open_spider(self, spider):
(...)
def close_spider(self, spider):
(...)
def process_item(self, item, spider):
(...)
這裡介紹三個 stage
- open_spider spider 開啟時會觸發, 可以在這個階段做連接資料庫的動作
- close_spider spider 關閉時觸發, 可以在這個階段記錄一些 log (ex. 爬蟲執行的結果)
- process_item 當 spider 執行時有建立 item 物件, 離開該執行區塊時會觸發 (表示該 item 資料被寫入完畢), 可以在此階段將該 item 上的資訊寫入資料庫
將上述三個部分的程式內容實作完成後, 還是有一些小地方要修改一下才跑得起來, 這些補充說明的部分如下。
robots.txt
Scarpy default 遵守 Robots exclusion standard, 會先嘗試在 domain 中尋找 robots.txt 的存在才允許進行 crawl, 要將此行為關掉, 修改 settings.py 如下
settings.py
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
Enabled Pipeline
如果有自行新增的 pileline 要執行, 或是希望蒐集到的圖片能如同筆者的需求, 透過 scrapy 自行下載 (如上面 item 範例中所述), 就要在這邊告知 scrapy, 一樣是修改 settings.py 如下
settings.py
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1,
'MySpider.pipelines.MySpiderPipeline': 300,
}
後面的數字愈小, 執行的順序愈優先; ImagesPipeline 是 Scrapy 內建的, 沒有特殊的需求可以直接使用此 pipeline。
以上就是改用 Scrapy 來作為爬蟲框架的重點整理, 有任何使用上的疑問或說明上的錯誤都歡迎留言給筆者。