Machine Learning Foundations 機器學習基石 (課程筆記)
由台大資工系 副教授 林軒田 提供的開放式課程, 關於教材內容皆可於 Youtube教學影片 及 投影片下載網址 取得。
Git Book傳送門
隨著文章的編寫, 發現用 Blog 單篇文章的形式呈現會讓整體知識的結構太過於線性, 所以重頭使用 Gitbook 編寫, 更完整的學習筆記可以前往參考, 這邊僅提供一些 Overview。
以下尚未整理, 請直接參閱 gitbook 最新更新。
Introduction
模仿人類學習的方式, 透過觀察 (data) 學習 (取出特徵、經過計算處理) 後得到有意義的技巧 (提升某項可以量化評估的表現)。
一些應用機器學習的時機
- 過於複雜 (不預期的狀況) 的系統不容易轉化成程式來處理
- 不容易寫出判定規則的系統
- 人尚未或無法即時判定的行為
- 過分客製化 (數量過多) 的反應
使用條件
- 具備 可理解的特徵 以及 可供量化評估改進的結果
- 不容易定義出規則 (容易定義則使用規則撰寫一般的程式處理即可)
- 有資料可供學習
Model Component
- Algorithm, learning algorithm 為挑選假說的演算法
- Data Set, D: {(X1,Y1), (X2,Y2), ... (XN,YN)}
- X 為 input 的特徵向量, Y 為 Output
- Hypothesis Set, 推論 X 與 Y 之間存在關係的假說集合
- f 理想上的 target function 可以完全地反應出所有的關係 (實際上 unknown), f: X → Y
- g 透過 algorithm 從 hypothesis set 中挑選出最接近 f 者
- A takes D and H to get g ≈ f, 機器學習是透過資料從假說中挑選最接近目標函式者, 用以推測訓練資料以外的其他資料結果
- Learning Model = A and H
Machine Learning vs Data Mining
資料探勘通常是對大量的資料中尋找有用的性質, 如果這個性質的目標是找出更好的 hypothesis, 則兩者的差異不大 或是 可相互幫忙。
Machine Learning vs Artificial Intelligence
人工智慧的目標在於經過計算之後可以得到具備智能的行為, 而機器學習是其中一種實現人工智慧的方法 (其他方法像是 決策數)。
Machine Learning vs Statistics
統計學是用資料推論一些未知的結果, 所以統計是機器學習中會使用到的其中一種工具。
Perceptron Learning Algorithm
這邊介紹一種簡單的 Hypothesis Set 的定義方式稱 "Perceptron" 來求一個是非題的解, 數學上的符號如下
Σ (i=1~d) wixi (再定義出一個 threshold 來二分這是非題的結果, y = {+1 , -1})
h(x) = sign ( Σ (i=1~d) wixi - threshold )
令 w0 為 -threshold、x0 為 1, 則化簡如下
h(x) = sign ( Σ (i=0~d) wixi ) = sign (wTx)
相當於取 w 與 x 兩個 d+1 維的向量內積。
目標是從 H 中挑選出最接近 f 的 g, 而這最接近的定義為在已經看過的資料中可以產出愈相同的 output , 但實際上整個 H 是一個無限大的集合, 所以 PLA (Perceptron Learning Algorithm) 的想法是嘗試先從中挑選出第一個 g0 (或稱 w0), 並不斷的在錯誤中修正。
演算法
If, sign (wTxn(t)) ≠ yn(t)
Let, wt+1 = wt + yn(t) xn(t)
Until no more mistakes.
想法是當計算的結果與預期的符號不同時, 表示匹配特徵向量 w 與 資料特徵向量 x 兩者間的角度過大或過小, 所以修正匹配特徵向量 w 使其遠離或靠近 x 一點 (方向視其預期結果的正負來決定)。
sign (wTx) 中, wTx = 0 在二維中是一條法相量為 wT 的直線二分其結果 y, 在高維度時則是劃分結果 y 的則是法相量 wT 的高維平面。
Linear Separability 線性可分
PLA 的終止條件是可以找出一個完全沒有錯誤的 w, 此時稱作線性可分; 而這個 wf, 可以完美的劃分開不同結果的資料, 使其與分割平面 (線) 都有 > 0 的距離 (因為計算結果與內積皆同向)
yn(t) wfTxn(t) (所有 input 包含發生錯誤的點) ≥ min( yn wfTxn ) > 0
討論 PLA 演算法修正的結果好壞的判定
wfT wt+1 = wfT (wt + yn(t) xn(t)) >= wfT wt + min( yn wfTxn ) > wfT wt
到此我們只證明了一半, 表示透過演算法可以不停地修正可以得到與 target 內積愈來愈大的特徵向量, 但內積愈大並不能表示兩個向量的夾角愈小 (方向愈接近), 也有可能是因為修正後的向量長度變長所造成的, 這就是我們後面所要證明的第二部分。
透過前式, 我們可以一路推導做了 T 次修正後如上的結果
因為我們僅在錯誤的時候做修正, 所以中間項的乘積會 < 0, 上式就是我們得到的向量長度 Upper bound
接著一樣透過前式, 我們可以一路推導做了 T 次修正後如上的結果
最後可以求出 cos θ 經過 T 次迭代後的收斂式子 (ρ 與 R 皆是我們導出的常數), 因此我們可知當今天的資料是 Linear Separability 時
- PLA 確實可修正 Wt 使其更加靠近 Wf
- 由 lower bound 可以知道經過有限次的迭代後, 此演算法會中止
- 綜合以上兩點所以 PLA 可以找到一條完美的分割線
得到以上的結果後, 對於 PLA 還是存在一些疑問, 包括了如何知道資料是線性可分 (Wf 存在), 如果是已知那實際上我們也就不需要做 PLA, 所以這部分通常是未知, 另一個問題是怎麼知道要做多久才會結束?
Noise
關於雜訊會有一些假設, 我們假設大部分的時候雜訊是很少的 (雜訊過多則學雜訊的意義反而較大), 則大部分的時候 yn = f (xn), 則當如果找到 g ≈ f 即得 yn = g (xn)
Pocket Algorithm
基於有效的挑選出完美的 g 其實是一個 NP-Hard 的問題, 所以這邊舉了一個簡單的演算法, 演算法的精神是建立在 PLA 不停地挑選犯錯更少的 Wt+1 出來, 直到夠多的迭代後以最終的結果為回傳值, 相較於 PLA 除了比對當前資料是否造成錯誤結果之外, Pocket Algorithm 要去計算所有資料的結果, 所以當今天資料是線性可分時, Pocket Algorithm 會比 PLA 慢, 但能確保有終止條件。
機器學習的分類
在整個學習的 Model 中針對控制變因的種類區分定義其特性。
以提供不同 yn 形式區分的學習方式
- Supervised 監督式, 提供匹配的問題與解答來教學 (其他方式的基礎)
- Unsupervised 分群的問題, 不提供 yn
- Semi-supervised 數量多無法窮舉時, 部分標記剩餘透過機器學習分類
- Reinforcement 單筆單筆的告知系統反應是 好 或是 不好, 不一定精確知道其輸入對應的輸出為何, 但有輔助判定的資訊
以提供資料方式區分的種類
- Batch 成批的資料訓練
- Online, sequentially 一個一個的逐步改善
- Active, sequentially 機器主動的方式來自動挑出盲點 (應用於標記資料需要高成本)
以資料內容區分的種類
- Concrete Features 具體有關聯性的特徵 (需有 domain knowledge)
- Raw Features 通常需要人或機器建立、抽取出具體的特徵, 以避免原始資料對於問題過於抽象
- Abstract Features 輸入資料完全不具任何意義, 同 raw features 一樣需要建立出特徵
機器學習的限制
最根本的現實是機器學習即便挑選的演算法以及假說設定的再好, 最終也只能代表 inside Data 能有不錯的表現, 關於 outside D 我們都是未知, 接下來就是對於我們是否能增加一些條件, 來對於這些未知的結果得到較為可靠的推論 (透過數學的工具)。
Topic I (Hoeffding's Inequality)
Sample (取樣) 的代表性, 假設取樣中某特徵呈現的機率為 ν 實際機率為 μ, 則兩者存在以下不等式的關係
P [|ν - μ| > ɛ] ≤ 2 exp (-2ɛ2N), ɛ 為誤差範圍、N 為取樣數
- 誤差愈大 或 取樣數愈大, 不等式右項就愈小, 表示發生的可能性愈低
- ν = μ 是 PAC (Probably Approximately Correct) 很大的機會是對的, 但還是有例外
Topic II
假定透過相同的 P 機率分佈作為產生 訓練資料(in) 及 測試資料(out) 的樣本, 這邊機率的意涵為 Data 透過特定 Hypothesis 產生對或錯的機率 (使用 Error 作為錯誤的機率)。
P [|Ein(h) - Eout(h)| > ɛ] ≤ 2 exp (-2ɛ2N)
所以當取樣夠多時
- Ein(h) ≈ Eout(h)
- 又當 Ein(h) 夠小時, g = f is PAC (Probably Approximately Correct)
- 說明了如何驗證一個 Hypothesis 的好壞, 但不保證被 Algorithm 挑選到
Topic III (Pick Algorithm)
挑選 Hypothesis 的限制, Ein(h) 最低不一定代表是最佳, 因為 sample 到不好的資料會讓 Ein(h)、Eout(h) 相距很遠, 當有選擇時, 會讓選出錯誤的 Hypothesis 機率增加 (更容易選到 overfitting 的假說)。
令有限 M 種的 Hypothesis, 由 Topic I Hoeffding's Inequality 知道個別 Hypothesis 選中不好的資料 (Ein(h)、Eout(h) 相距很遠) 的機率不高, 所以 Σ (i=0~M) PD[BAD of D]≤ 2 M exp (-2ɛ2N), 可得知當取樣個數夠多時 且 有限個數 M 的 H, Ein(g) ≈ Eout(g) is PAC 一樣會成立。
M 的挑選是個取捨, 過小的話可以讓選中不好的 g 機會降低, 但是可以選的選項太少反而不一定存在可以挑出夠小的 Ein(h), 太大的 M 則是讓選出不好的 g 機率增加。

Topic IV 如何收斂 Hypothesis Set
∞ 多個 Hypothesis 會讓不等式的 Upper Bound 沒有意義, 原因在於 Set 之中其實存在許多相似重疊的 Hypothesis, 接著我們要收斂 Set 裡的個數, 先嘗試對 Hypothesis 做分類, 方法是從 Data 的角度看待這些 Hypothesis 是將其歸類為何 ex. binary classification output y = {+1, -1}。
Effective Number of Lines 定義為將 output 劃分不同種類的可能性 (≤ 2N)
- 僅一筆資料時, 存在兩種 分割線/高維平面 將其 output 分為 +1 或 -1
- 二筆資料時, 存在四種 分割線/高維平面 將這兩個資料特徵向量 output 分為 +1 或 -1
- 三筆資料時, 最多存在八種 分割線/高維平面, 但如果三點共線時則僅六種 (+1,-1,+1), (-1,+1,-1) 的 分割線/高維平面 不存在
- 四筆資料時, 共平面時 (想像成二維), 則最多只有 14 種 (對角線為相同 output 的分割線/高維平面 不存在)
- 五筆資料時, 共平面時 (想像成二維), 則最多只有 22 種
Dichotomy 指透過 Hypothesis 對所有 x (input data) 運算的結果, Dichotomies H(x1, x2, ... xN) 表示這些不同 結果的集合, 集合內個數上限稱為 Effective Number of Lines。
Target 目標在於找到一個方法, 可以有效的將 ∞ 多個 Hypothesis 找到分類後的個數可以 << 2N (大於 2N 會讓 Top III 的不等式右項無法收斂), 而這個目標的關係式稱作
Growth Function: mH(N) = max | H(x1, x2, ... xN) | ≤ 2N
Break Point 第一個資料點 K 使得 mH (K) < 2K, 在 K < N 皆會成立。
Example
- Growth Function for Positive Rays (大於某個 threshold 結果為正), 則 ∞ 的 H 為 h(x) = sign( x - threshold ), 但 Growth Function 為 mH(N) = N+1, 因為僅有 N+1 種可以放置 threshold 的組合。
- Growth Function for Positive Intervals (在某個區間內時, 結果為正), 則 ∞ 的 H 為 h(x) = +1 if x ∈ [l, r), -1 otherwise, 但 Growth Function 為 mH(N) = (C N+1 取 2) + 1 (all -1 的 case)。
- Growth Function for Convex Sets (凸多邊形內的區域結果為正), 其中一種可能是將所有資料排成圓形, 並將結果為正的點連線成多邊形, 此時 2N 所有種排列皆可以產生, 因為 Growth Function 是取 max, 所以僅需要造出這組即可得知 Growth Function 為 mH(N) = 2N。
成長函數為 2N 的這 N 個 input 被稱作 Shattered。
- No break point: mH(K) = 2N
- Exist break point K: mH(K) = O(NK-1) 之後會證明
Proof
令 B(N,K) 為 Bounding Function, 其值是要抽象於 Growth Function 外只在乎其 Dichotomies 上限, 解讀為 N 個 input 中任意取 K 項的不同 Dichotomy 個數 (當 K 為 break point 時), 而這邊重點又在於已知任取 K 項時不會 Shattered (種類 < 2K), 那是否能找得出 B(N,K) ≤ 多項式的複雜度 (個數)。
B(N,K) = 2α + β (拆分為 α 表示 Dichotomy 中僅最末項不同的個數, β 是剩餘個數)
α + β ≤ B(N-1,K) (去掉最末項後 僅 留下不同的 Dichotomy 個數, 因為 B(N,K) 告訴我們任 K 項不 Shattered, 所以剩下的項本身也不會 Shattered)
α ≤ B(N-1,K-1) (若任取 K-1 項會 Shattered = 2K-1, 則加上之前去掉的最末項 = 2K, 與 Bounding Function 定義衝突)
B(N,K) ≤ B(N-1,K) + B(N-1,K-1) (替換上式可得知)
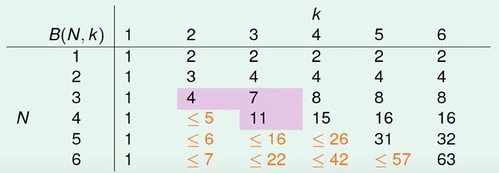
透過以上關係式, 可以用數學歸納法證明以下不等式, 而 RHS 的最高項為 Nk-1
當 N = 1 時代入很容易得知成立, 假設 N = N' 也成立, 透過以下推導得知 N = N'+1 也會成立, 得證
所以得知, 當 Break Point 存在時, 其 mH(K) 數量跟 N 的關係會是 polynomial (上式其實可以反向再證明 LHS = RHS, 不僅僅是 upper bound)
VC Dimension (dvc) = 'minimum K' -1
Noise
Is VC bound work fine with Noise.
假設 output 存在一個機率分佈 (含雜訊造成的結果) 稱作 P(y|x) = f(x) + noise, mini-target 的觀念是挑選機率分佈中發生機率較高者為 output, 更進一步說 P(x) 機率高者 (表示 input 常被選中) 時我們更要挑選 mini-target 的 P(y|x)。